
Optical character recognition (OCR) is growing at a projected compounded annual growth rate (CAGR) of 16%, and is expected to have a value of 39.7 billion USD by 2030, as estimated by Straits research. There has been a growing interest in OCR technologies over the past decade. Optical character recognition is the technological process for transforming images of typed, handwritten, scanned, or printed texts into machine-encoded and machine-readable texts (Tappert, et al., 1990). OCR can be used with a broad range of image or scan formats – for example, these could be in the form of a scanned document such as a .pdf file, a picture of a piece of paper in .png or .jpeg format, or images with embedded text, such as characters on a coffee cup, title on the cover page of a book, the license number on vehicular plates, and images of code on websites. OCR has proven to be a valuable technological process for tackling the important challenge of transforming non-machine-readable data into machine readable data. This enables the use of natural language processing and computational methods on information-rich data which were previously largely non-processable. Given the broad array of scanned and image documents in open government data and other open data sources, OCR holds tremendous promise for value generation with open data.
Open data has been defined as “being data that is made freely available for open consumption, at no direct cost to the public, which can be efficiently located, filtered, downloaded, processed, shared, and reused without any significant restrictions on associated derivatives, use, and reuse” (Chidipothu et al., 2022). Large segments of open data contain images, visuals, scans, and other non-machine-readable content. The size and complexity associated with the manual analysis of such content is prohibitive. The most efficient way would be to establish standardized processes for transforming documents into their OCR output versions. Such machine-readable text could then be analyzed using a range of NLP methods. Artificial Intelligence (AI) can be viewed as being a “set of technologies that mimic the functions and expressions of human intelligence, specifically cognition and logic” (Samuel, 2021). OCR was one of the earliest AI technologies implemented. The first ever optical reader to identify handwritten numerals was the advanced reading machine “IBM 1287,” presented at the World Fair in New York in 1965 (Mori, et al., 1990). The value of open data is well established – however, the extent of usefulness of open data is dependent on “accessibility, machine readability, quality” and the degree to which data can be processed by using analytical and NLP methods (data.gov, 2022; John, et al., 2022).
OCR can be used to automate and enhance business processes involving data sources which are not ready for direct processing. Organizations can create OCR solutions to address critical problems. For instance, automated OCR can be used to identify document types, digitize handwritten text, and parse through the data to create data visualizations and feed into a GUI dashboard for exploratory review or further empirical analysis. OCR can be aligned with complex organizational / business rules and used for document management and decision support systems. OCR can also be used to develop assistive solutions for customers or employees with vision impairment via OCR and NLP applications that convert written text into audible speech. Other use cases of OCR technology include automated evaluation of test answers, recognition of street signs (e.g., Google Street View uses OCR methods to help its users search for local landmarks), and searching through the content (e.g., Dropbox uses the OCR feature to scan through relevant content) and text extraction from image (e.g., Google lens).
There are many ways to classify OCR systems – in one such useful classification, they have been categorized into two groups depending on the nature of input: handwritten content identification OCR systems and machine-printed content identification OCR systems. Machine-printed character recognition is a relatively simple problem because the content-characters are usually of uniform dimensions, possess a high degree of standardization and form, and the characters’ positions on the page can be predicted. Hence, OCR is viewed as a largely solved problem in machine-printed content identification. However, handwritten content identification is still acknowledged to be a difficult task. Unlike printed text, handwritten text cannot be converted easily with a comparable degree of accuracy into machine-readable content due to the wide variation in the representation of alphanumeric characters, the presence of different handwriting styles, minimal standardization of visual form, and, often, non-aligned image or document properties.
The OCR workflow combines multiple phases as described by Pandey (2020):
- Source data input – this phase involves the use of an external optical device, such as a scanner or camera to generate images that contain relevant alphanumeric text or symbols.
- Data preparation – covers various preprocessing operations, such as noise removal, to enhance source image quality and alignment of image with required standardized input format.
- Partitioning – multiple characters in the image are split into individual items in this phase, so that a recognition engine can process the partitioned characters appropriately.
- “Feature extraction” – the partitioned characters are further “processed to extract different features.” The characters are then ‘recognized’ based on their alignment with these features.
- Classification – based on partitioning and feature extraction, the target image’s features are mapped to several categories and classified to appropriate values.
- Options – characters within source files can be classified using multiple techniques for pattern recognition using fundamental and statistical approaches.
- Validation and improvement – Upon the completion of initial classification exercises, it may be observed that the results are rarely perfect. This is especially true for handwritten content with multiple authors, multifaceted fonts, and intricate languages. Quantitative, conceptual, linguistic, and probabilistic remedial approaches and fine tuning can be performed to improve the accuracy of OCR systems.
The number of academic labs and organizations researching topics on AI methods for character recognition has expanded significantly during the past several years. Numerous open source and proprietary solutions have been developed: Tesseract, TrOCR, Keras-OCR, DOC-Tr, Kofax-Omnipage, Adobe Acrobat Pro DC, and Easy-OCR. Scanned documents are generally saved in PDF format, which makes it very hard to interact with the content in the document. Digitized scans can be converted into editable Excel format using a capable OCR application, such as Cisdem PDF Converter OCR or ABBYY FineReader, which makes scanning to Excel considerably easier. Both deliver fairly accurate OCR results and allow users to convert scans to various frequently used output formats.
However, even after decades of extensive research, AI-OCR solutions with human-like abilities to ‘read’ handwritten text and symbols have remained largely elusive.
A team at the Rutgers Urban and Civic Informatics Lab (RUCI Lab) has been working on an adaptive digit recognizer mechanism trained on a customized MNIST dataset (trained on MNIST + custom digits) that can better predict digits written by a user. The core idea is to use a form of adaptive AI process to support underlying machine learning algorithms to create a template adaptable for local applications of OCR (Samuel, et al., 2022).
To illustrate the concept of artificially intelligent smart-OCR, the RUCI Lab team created a dataset of hundreds of custom digits with Microsoft Word’s draw function. They converted the custom digits into MNIST format, appended it to the original MNIST dataset, and randomized the order to get a balanced mix. To ensure that the resulting model can predict values even for slightly rotated or angled images, they rotated hundreds of additional digits and appended them to the main dataset. They then used convolutional neural networks (CNNs) for digit recognition since CNNs work well with images. They then used the customized MNIST dataset to train a CNN (Convolutional Neural Network) based on tens of thousands of images of handwritten numbers from 0 to 9 displayed as 28 by 28-pixel monochrome images. They achieved above 99% accuracy, as displayed in the graph below (Figure 1).
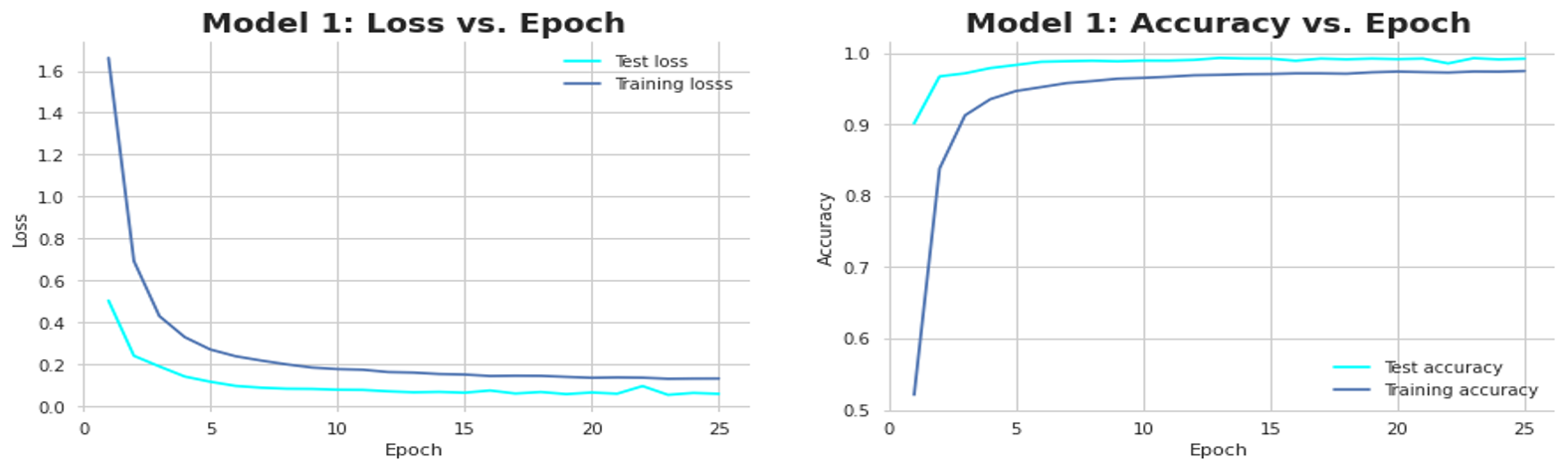
Figure 1: Smart-OCR accuracy and loss with local adaptability.
OCR improvements and experimental results from multiple labs and corporations demonstrate the growing effectiveness of AI technologies in addressing the machine-readable digitization of text in images, visuals, and scanned documents. This also presents a great opportunity for governments and businesses. Given the high value creation potential of OCR technologies, it is important to support the application of OCR technologies with appropriate policy mechanisms. The state of New Jersey has implemented a robust open data program, as evidenced by one of the state’s prominent open data portals. Our analysis of the open data ecosystem revealed troves of PDF documents and other scanned or image files with valuable information (i.e., Official site of Township of Lakewood 2010-2019 Planning Board Approvals, and a near-historical ‘Master Plan’ from 1982). Much of the data in the PDF documents and image files cannot be processed efficiently using quantitative and NLP computational methods due to the inability of machines to read such data directly. Hence, even though the state has acted proactively and made the data available, the intent of data democratization remains unfulfilled due to the lack of machine-accessibility and usability (Samuel, et al., 2022b). Hence, we strongly recommend policy discussions for the state of New Jersey and for all governments and organizations facilitating the availability of open data on the following items:
- Open data portals need to use OCR mechanisms to make current and future streams of non-machine-readable data available in machine-readable formats.
- Open data portals need to provide test results on accuracy achieved for OCR transformed open data by dataset category – this will inform users on the viability of using state-of-the-art OCR solutions for specific datasets.
- Governments and organizations must encourage local entities to facilitate OCR solutions at the source and user levels.
- Use case development and open data user education as a near term solution – there is a need to develop and showcase OCR implementations for critical datasets, such that users can easily download and apply these mechanisms to relevant datasets.
- Governments and organizations must invest in research supporting AI-driven smart OCR solutions with adaptability to local content to maximize the potential for value creation from open data.
Additional research and debates are needed on the pros and cons of OCR technologies. There is room for further development of AI-driven smart OCR technologies, and we hope that this important human-friendly system receives sufficient attention and support from governments and all relevant organizations.
References:
- Tappert, C. C., Suen, C. Y., & Wakahara, T. (1990). The state of the art in online handwriting recognition. IEEE Transactions on pattern analysis and machine intelligence, 12(8), 787-808.
- Chidipothu, et al., 2022, Artificial Intelligence and Open Data for Public Good: Implications for Public Policy, Retrieved on 4th December 2022, URL: https://policylab.rutgers.edu/artificial-intelligence-and-open-data-for-public-good-implications-for-public-policy/
- Mori, S., Suen, C. Y., & Yamamoto, K. (1992). Historical review of OCR research and development. Proceedings of the IEEE, 80(7), 1029-1058
- Samuel, J. (2021). A call for proactive policies for informatics and artificial intelligence technologies. Scholars Strategy Network. Url: https://scholars.org/contribution/call-proactive-policies-informatics-and
- Business case for open data at resources.data.gov. Retrieved May 27, 2022, from https://resources.data.gov/resources/open-data/
- John, et al., 2022, Catalyzing the Information Economy: Moving Towards Strategic Expansions of Open Data-Driven Value Creation. Retrieved on 4th December 2022, URL: https://policylab.rutgers.edu/catalyzing-information-economy-moving-towards-strategic-expansions-open-data-driven-value-creation/
- Samuel, J., Kashyap, R., Samuel, Y. and Pelaez, A. Adaptive cognitive fit: Artificial intelligence augmented management of information facets and representations. International Journal of Information Management 65 (2022) 102505. https://doi.org/10.1016/j.ijinfomgt.2022.102505
- Samuel, J., Brennan-Tonetta, M., Samuel, Y., Subedi, P. and Smith, J. “Strategies for Democratization of Supercomputing: Availability, Accessibility and Usability of High Performance Computing for Education and Practice of Big Data Analytics”, Journal of Big Data – Theory & Practice, 2022.
- Pandey, A. G. C., How to improve OCR Accuracy? Retrieved on 4th December 2022, URL: https://medium.com/@techcapper/how-to-improve-ocr-accuracy-124d2ebe0cd2